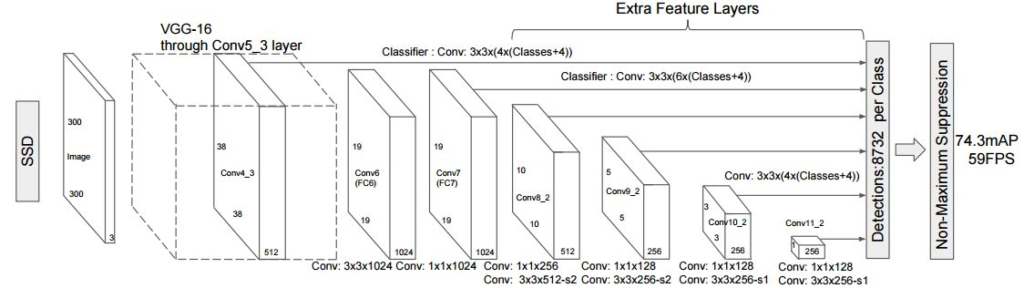
SSD: Single Shot MultiBox Detector [1]
1、方法简介
SSD主要有以下几个主要特点
- 特征提取主干网络:VGG16,去除全连接层fc8,fc6 和 fc7层转换为卷积层,pool5不进行分辨率减小,在fc6上使用dilated convolution弥补损失的感受野;并且增加了一些分辨率递减的卷积层;
- SSD摈弃了proposal的生成阶段,使用anchor机制,这里的anchor就是位置和大小固定的box,可以理解成事先设置好的固定的proposal
- SSD使用不同深度的卷积层预测不同大小的目标,对于小目标使用分辨率较大的较低层,即在低层特征图上设置较小的anchor,高层的特征图上设置较大anchor
- 预测模块:使用3×3的卷积对每个anchor的类别和位置直接进行回归
- SSD使用的data augmentation对效果影响很大
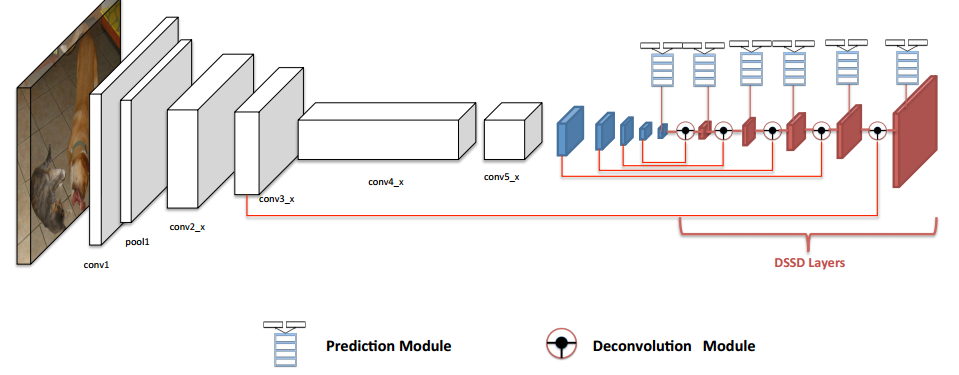
二、DSSD : Deconvolutional Single Shot Detector [2]
1、Motivation
模仿FPN进行特征融合的思路,使用反卷积对高层特征上采样后与浅层特征结合,增加浅层的语义信息来提高小目标检测的准确性。
2、做法
网络的框架图如下:
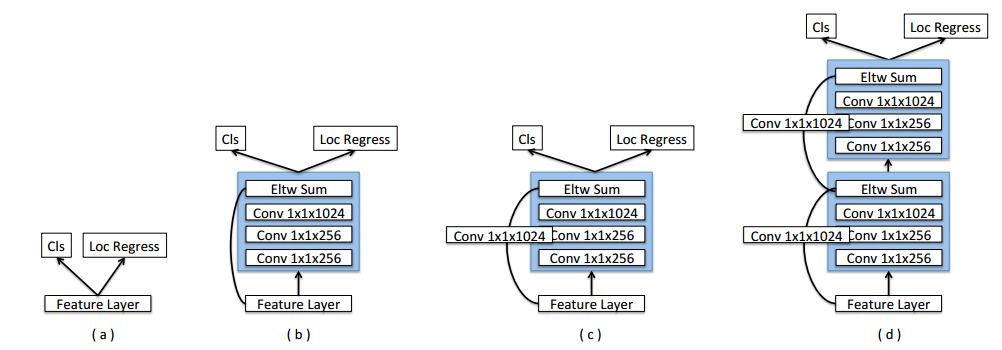
<1> Prediction Module
提出了下面比SSD (a)略复杂的预测模块(b,c,d),作者的ablation study表明(c)最好,在SSD300的基础上voc结果可以提升0.7%。
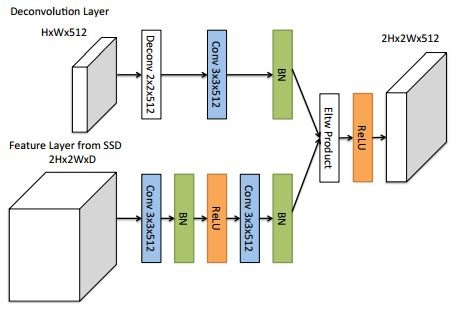
<2> Deconvolution Module
3、效果
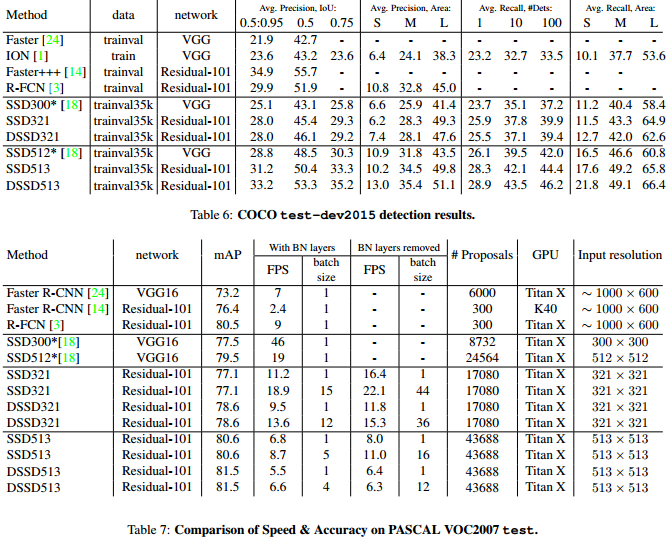
三、Receptive Field Block Net for Accurate and Fast Object Detection [3]
1、Motivation
- 模仿人的感受野,提出新的特征提取模块。
- 当前效果靠前的检测器大多是基于Resnet101的,像SSD这样基于轻量级VGG的方法,虽然速度很快但是精度不高。作者认为通过简单的增强轻量级网络的特征可以提升检测器的性能
2、做法
<1> RFB (Receptive Field Block)
简单地说就是在Inception module的每个分支后面增加一个相应的dilated convolution,下面是两种RFB结构。
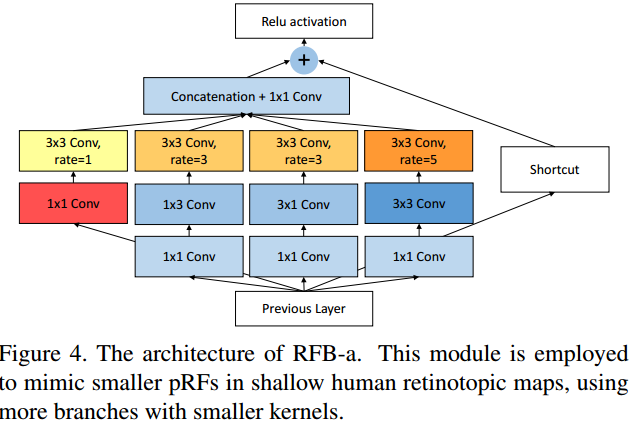
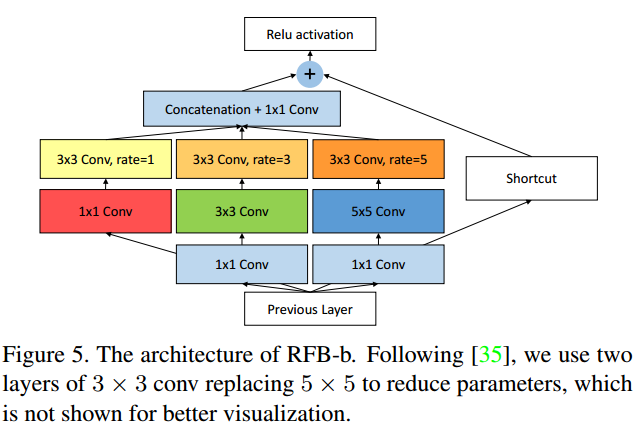
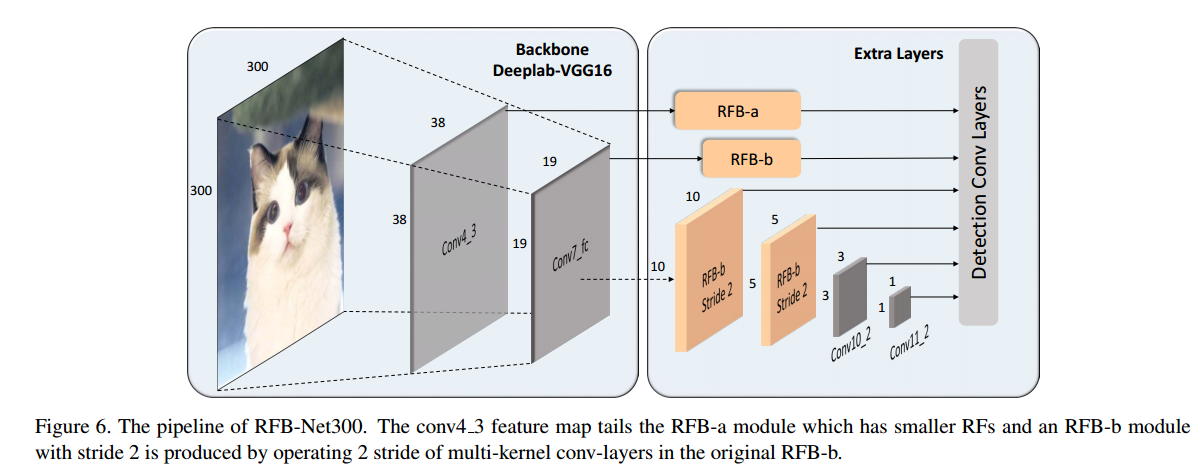
<2> 与SSD结合
作者在SSD的两个地方使用了RFB,一是在负责预测的VGG特征图与类别和位置预测模块之间,另一个是替换了前面几个增加的extra layers模块。
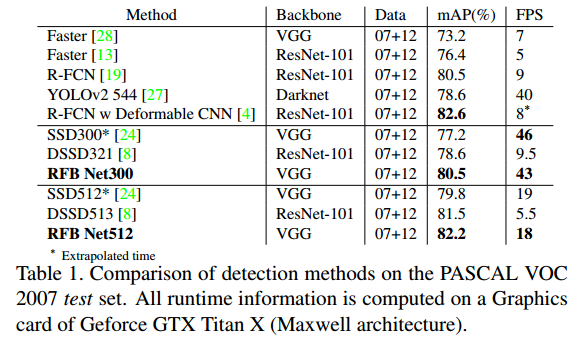
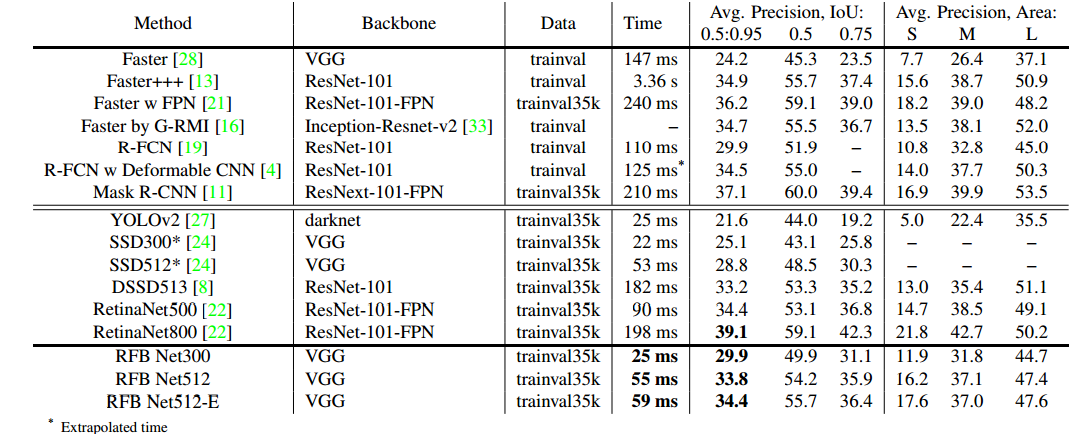
3、效果
RFB-SSD的效果很好,在voc上提升了约3%,速度也损失的较少。在coco上,RFB 512-E甚至和Retina500达到了一样的精度,而且速度更快。这里RFB 512-E是在上面说的SSD+RFB的基础上增加了两个改进:① 在RFB中增加一个7 x 7 kernel的分支;② fc7上采样和conv4_3融合后再使用RFB-a,提升小目标的检测效果。
4、其他细节
- 需要注意的是作者在代码中除了VGG的卷积层,所有新增加的卷积层都有BN层,BN层的作用应该也很大
- 相对于原始SSD,作者认为对于小目标,密集anchor更有效,因此在conv4_3设置了更多anchor(4个->6个),不过voc上ablation study只提升了0.2%
- 训练时先warm up
四、Single-Shot Refinement Neural Network for Object Detection [4]
1、Motivation
想要结合two-stage方法和one-stage方法的优点。
2、做法
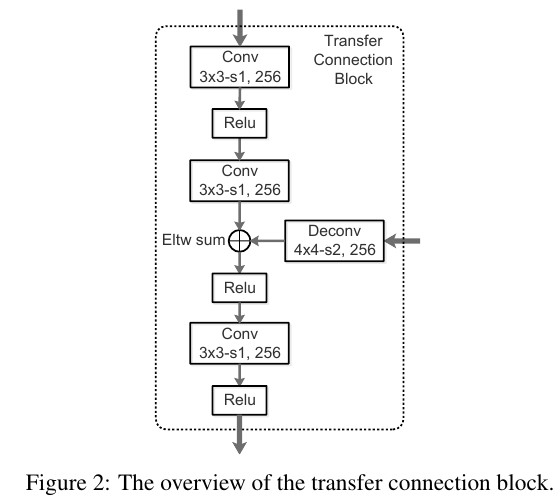
RefineDet可以简单的理解为两个SSD级联,第一个SSD与原始SSD基本一样,只是对anchor的进行二分类,同时修正anchor的位置;第二个SSD以第一个SSD输出的修正过的boxes为acnhor(根据前景得分进行negative样本滤除),进一步refine。两个SSD由Transfer Connection Block连接,可以理解成FPN的特征融合结构。

3、效果
voc07上比RFB-SSD低0.5%左右,voc12上比RFB-SSD低1.1%(单模型结果)。表中“+”代表使用Fast RCNN中的multi-scale测试策略,即将图像flip、缩放后的检测结果与原始检测结果ensemble。
速度上应该比RFB-SSD慢,RFB-SSD300在Geforce GTX Titan X(Maxwell)上可以达到43fps,RefineDet在 NVIDIA Titan X上40fps。
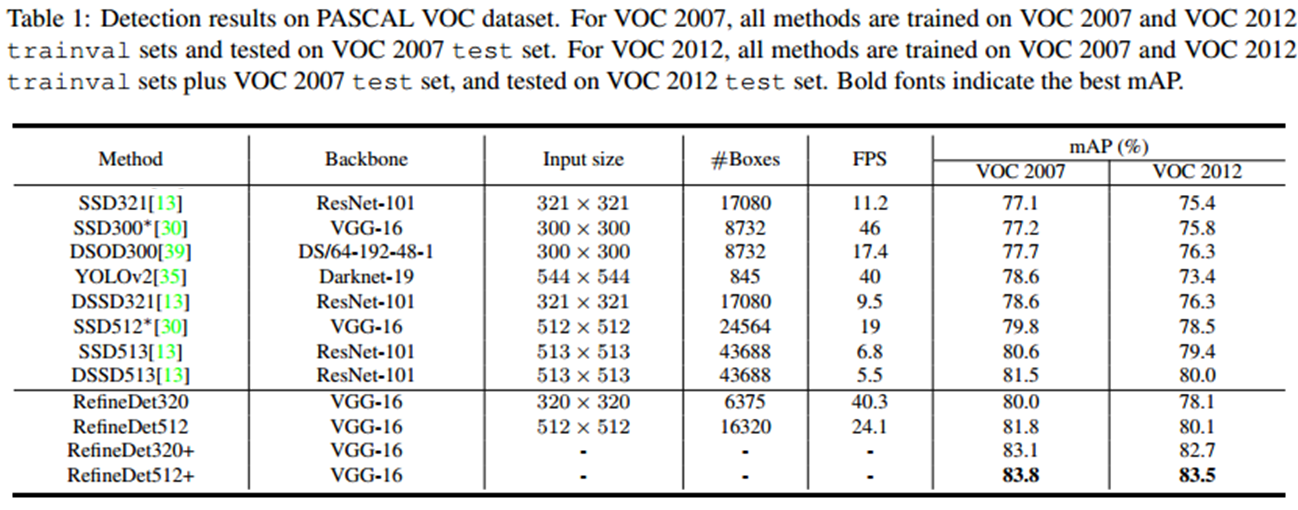
但是RefineDet也做了主干网络是Resnet的实验,在COCO上RefineDet512单模型结果要比RetinaNet500好2%。
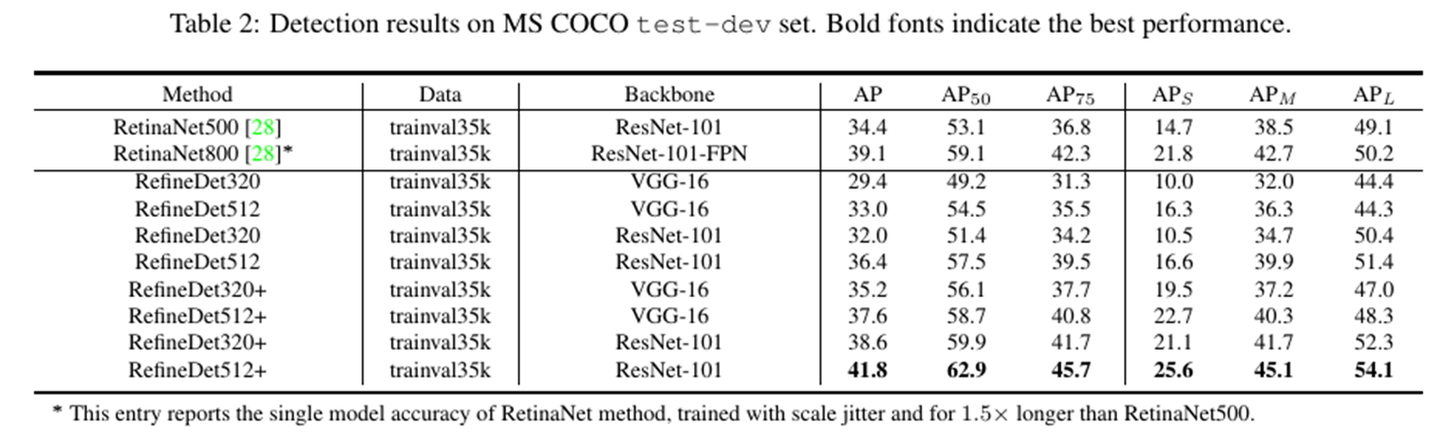
4、其他细节
- conv4_3和conv5_3上都加了L2 norm
- anchor scale:4乘以相应层相对原图的stride
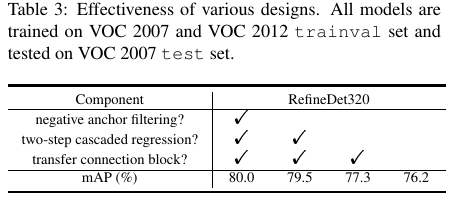
- Ablation study表明:两步级联的修正最重要,如果在第二个SSD中使用原始固定的anchor,效果会下降2%.
五、Accurate Single Stage Detector Using Recurrent Rolling Convolution [5]
1、做法
为了实现更加充分的特征融合,RRC不仅采取了FPN的top-down融合,还增加了bottom-up的低层特征直接与高层特征的融合,以及侧向加深网络深度(类似RNN的结构),网络结构图如下:
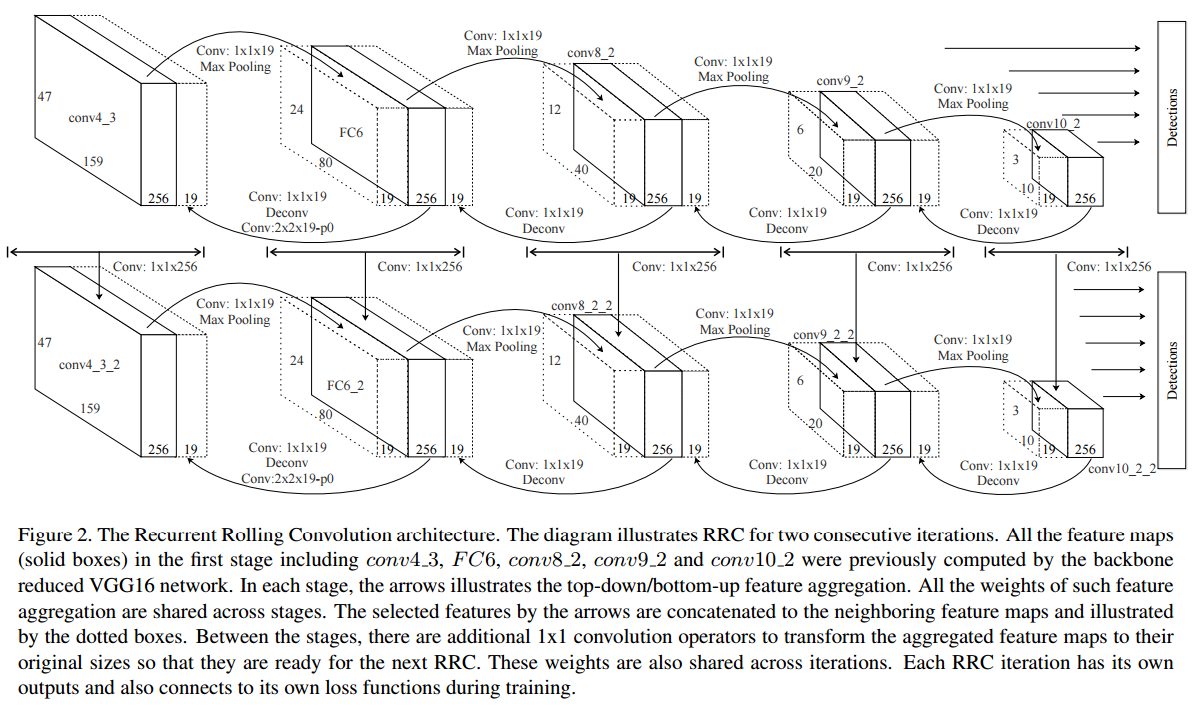
2、效果
RRC只在KITTI上做了实验,单模型只给出了车辆的test结果。
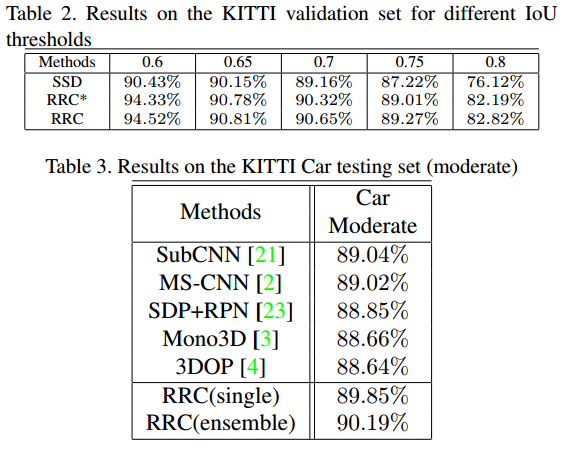
3、其他细节
- Deconvolution参数不学习,使用双线性插值
- 每个iteration(就是网络图中的每一行)都有自己loss,同时优化,deep supervision
- 测试时只使用最后一个iteration的检测结果
- RRC中的anchor设置非常的密集,每一层有四个scale(SSD一个)
六、特征融合类
1、FSSD: Feature Fusion Single Shot Multibox Detector [6]
- FPN特征融合的变种,做法:
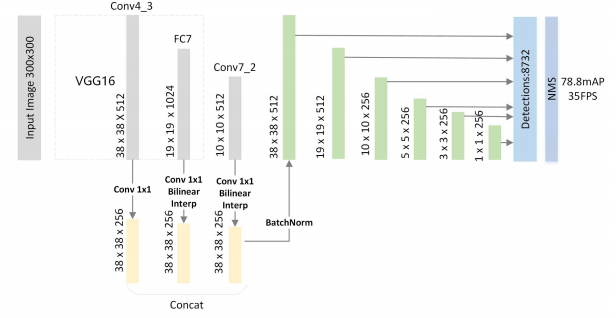
- 效果

2、Feature-Fused SSD: Fast Detection for Small Objects [7]
- 把conv5_3反卷积后与conv4_3融合,实现非常简单
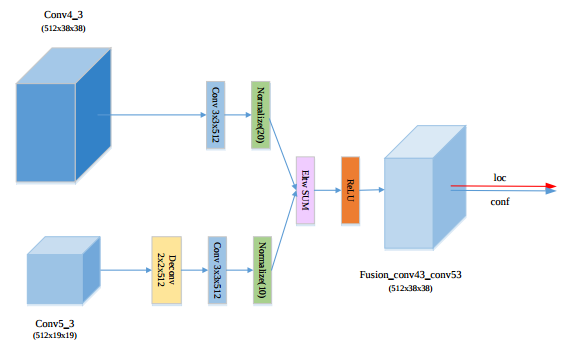
- 效果:voc07上,输入尺寸为300×300时可以比SSD提升1.7%,输入为500×500时提升较少(1%左右)。
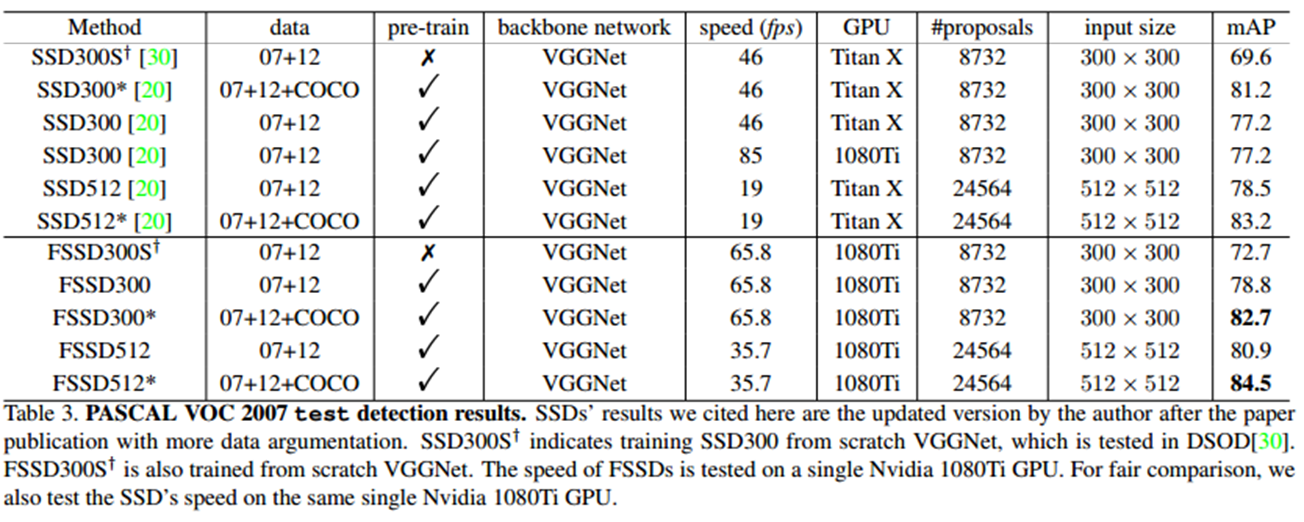
七、总结
我觉得RFB-SSD在速度和精度上都达到了很好的效果,同样的主干网络(如VGG)下,
准确性:RFB-SSD > RefineDet > FSSD ? DSSD > SSD
速度:SSD > FSSD~RFB-SSD > RefineDet > DSSD
Reference
[1] Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.Y., Berg, A.C.:
SSD: Single shot multibox detector. In: ECCV. (2016)
[2] Fu, C.Y., Liu, W., Ranga, A., Tyagi, A., Berg, A.C.: DSSD: Deconvolutional single
shot detector. arXiv preprint arXiv:1701.06659
[3] Liu, S., Huang, D., & Wang, Y. :Receptive Field Block Net for Accurate and Fast Object Detection. arxiv preprint arXiv:1711.07767
[4] Zhang, S., Wen, L., Bian, X., Lei, Z., Li, S. Z. :Single-Shot Refinement Neural Network for Object Detection. arxiv preprint arXiv:1711.06897
[5] Ren, J., Chen, X., Liu, J., Sun, W., Pang, J., Yan, Q., Tai, Y.W., Xu, L.: Accurate
single stage detector using recurrent rolling convolution. In: CVPR. (2017) 752–760
[6] Li, Z., Zhou, F. FSSD: feature fusion single shot multibox detector. arXiv:1712.00960
[7] Cao, G., Xie, X., Yang, W., Liao, Q., Shi, G., & Wu, J.: Feature-fused ssd: fast detection for small objects. arXiv:1709.05054


文章价值很高,值得学习
谢谢,共同学习